「Tokyo HoloLens ミートアップ vol.11 忘年会スペシャル!」で展示,LTしましたで展示した「隣にVTuber」のがんばったポイントを書いていきます.
推し
学習モデル
- 因幡はねるさんは長時間の動画が多いので自己紹介動画を参考にしました.
画像データ
- 動画から1秒間に5枚の頻度でjpg画像を出力してラベリング用データにしています.(およそ400枚)

ラベリング
- 表情は最低限目と口の状態がわかるようにlandmarkを8点設定しました.
- 右目上
- 右目下
- 左目上
- 左目下
- 右口角
- 左口角
- 上唇
- 下唇

学習モデルを作り始めたのがMeetup当日だったので400枚x8点のラベリングは2時間程度で終わってます.
顔の認識は動画と同じスケールで十分に検出できる精度が出ていましたが,表情認識では1/2のスケールの方が元動画以外の動画でも認識精度が出ていました.
キャプチャシステム
OBS
- 因幡はねるさんの表情認識を行う部分はOpenCVの
cv::VideoCaptureを使っていたため,mp4動画とWebカメラのみ入力データとして使えませんでした. - Meetupでは動画をループさせたりYoutubeの動画を直接認識させたかったので,OBSとOBS-VirtualCamを利用しました.
- OBS-VirtualCamはOBSでの出力を仮想Webカメラとして出力することでOpenCVの
cv::VideoCaptureで映像を取得できるようになります. - OBSからのキャプチャを利用することにより実装負荷を下げて動画の種類(生放送でも)を問わずに認識に利用ができる.
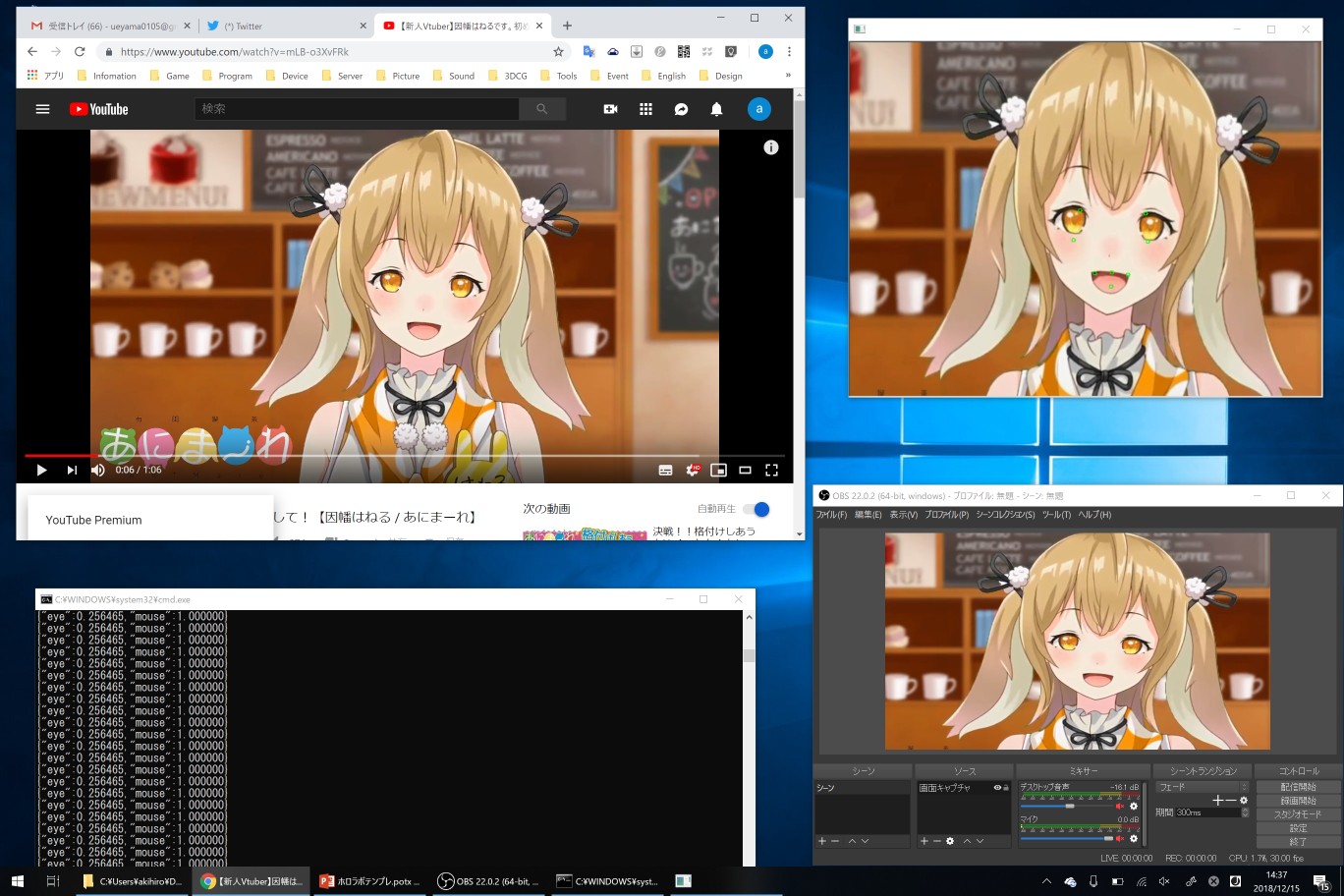
- 画像左上がYoutubeの動画
- 右下はOBSで取得したデスクトップキャプチャ映像
- 右上が隣にVTuberシステムによるOBSから取得した映像に対して表情認識を行っている
- 左下が表情認識結果から正規化した目と口の値
- 正規化したデータをHoloLensに送信している
HoloLens側
VRMモデル
- 因幡はねるさんのVRMモデルはかんにゃんさんのモデルをお借りしました.(かわいい)
をそれぞれIKで移動できるようにすることで,床に体育座りしてもらったり,椅子に座ってもらったり,ゲームパッドを持ってもらうことができるようになってます.



- 因幡はねるさんの動画から取得できる表情は目と口の動きだけで動きが足りないので,周期的に体をゆらゆらさせるスクリプトを追加することでロボット感を薄めました.
まとめ
- 現状は因幡はねるさんの初期衣装の時の表情しか認識できない
- もっとlandmarkの設定数を増やして画像データ数を増やすことで精度と表情の種類を増やせる
- Youtubeなどの配信で2Dでの配信を行っていて,3Dのモデルが公開されているVirtualYoutuberであれば,誰でも隣にいてくれるようにすることができる
- 表情認識まではPC側で行っているので表示端末側の負荷を抑えることができ,HoloLens以外のスマホARやVRのHMDでも対応できる(「特定の端末,環境でしか視聴できない」を防げる)
動画配信から表情認識しているので配信側の追加は必要ない
仕事している隣でさなねるしてて欲しい